
Table of Contents
ในระบบ AI สมัยใหม่ โมเดลภาษาขนาดใหญ่ (LLMs) เช่น GPT และ Claude ได้สร้างความตื่นเต้นด้วยความสามารถในการประมวลผลและสร้างข้อความที่มีลักษณะคล้ายภาษามนุษย์ อย่างไรก็ตาม เพื่อให้ทำงานได้อย่างมีประสิทธิภาพ โมเดลเหล่านี้จำเป็นต้องได้รับข้อมูลที่เกี่ยวข้องอย่างถูกต้อง ไม่ว่าจะเป็นข้อมูลอินพุตจากผู้ใช้ ข้อมูลการสนทนาที่ผ่านมา หรือสรุปเนื้อหาจากไฟล์ การมีข้อมูลที่เกี่ยวข้องที่ชัดเจนและมีการจัดระบบไว้อย่างดีจะช่วยปรับปรุงคุณภาพของผลลัพธ์ที่ได้
โปรโตคอล Model Context Protocol (MCP) เป็นโปรโตคอลแบบเปิดที่กำหนดวิธีการจัดระเบียบและส่งผ่านข้อมูลที่เกี่ยวข้องให้กับ LLMs โดยมาตรฐานนี้ได้กำหนดวิธีการจัดการข้อมูล (เช่น สรุปไฟล์หรือข้อมูลจากภายนอก) เพื่อให้ส่วนประกอบ AI ของคุณสามารถนำไปใช้งานได้อย่างราบรื่น
ในบทความนี้ เราจะสร้างเซิร์ฟเวอร์ MCP ด้วยเครื่องมือตัวอย่างสองตัวคือ
read_csv_summaryเครื่องมือนี้จะอ่านไฟล์ CSV ที่ชื่อsample.csvแล้วแสดงสรุปที่รวมจำนวนแถวและคอลัมน์read_parquet_summaryเครื่องมือนี้จะอ่านไฟล์ Parquet ที่ชื่อsample.parquetแล้วแสดงสรุปเนื้อหาภายในไฟล์
เพื่อบริหารจัดการสภาพแวดล้อมของเรา เราจะใช้แพ็กเกจ uv และติดตั้งแพ็กเกจ mcp[cli], pandas และ pyarrow ผ่าน uv เพื่อให้โปรเจ็กต์ของเรามี dependency ครบถ้วน
บทความนี้จะอธิบายทุกขั้นตอนอย่างละเอียดและชัดเจน แม้ว่าคุณจะไม่ใช่นักเขียนโปรแกรมก็ตาม โดยมีตัวอย่างโค้ดและคำอธิบายที่ช่วยให้คุณเข้าใจการทำงานของแต่ละส่วนในเซิร์ฟเวอร์ MCP
MCP คืออะไรและทำไมต้องใช้?
ก่อนที่เราจะลงไปดูโค้ด จำเป็นต้องรู้ว่า MCP (Model Context Protocol) คืออะไร พื้นฐานทางเทคนิคของมันเป็นอย่างไร และข้อดีที่มันมอบให้กับระบบ AI สมัยใหม่คืออะไร
MCP คืออะไร?
Model Context Protocol (MCP) คือ framework มาตรฐานที่ออกแบบมาเพื่ออำนวยความสะดวกในการส่งข้อมูลระหว่างแอปพลิเคชัน AI กับ data source หรือ tools ภายนอกให้ทำงานได้อย่างราบรื่น พูดง่ายๆ ก็คือ MCP ช่วยจัดเก็บและส่งต่อข้อมูลที่ LLM ต้องการ เพื่อสร้างคำตอบที่ถูกต้องและทันเวลา
โดยภาพรวม MCP รับรองว่าเมื่อคุณส่งข้อมูลให้กับ LLM สำหรับการประมวลผล ข้อมูลที่จำเป็นจะถูกจัดเรียงอย่างเป็นระบบ ซึ่งมักจะรวมถึง
User Input: คำถามหรือการโต้ตอบที่ผู้ใช้เริ่มต้น
Historical Data: การสนทนาหรือการโต้ตอบที่ผ่านมา ที่ช่วยสนับสนุนคำถามในขณะนั้น
Configuration Settings: พารามิเตอร์ เช่น ภาษา โทนเสียง token limits และการตั้งค่าสำหรับแต่ละแอปพลิเคชัน
มาตรฐานนี้ช่วยลดความไม่ชัดเจนและทำให้ LLM เข้าถึงข้อมูลที่ครบถ้วนและมีระบบ ซึ่งเป็นสิ่งจำเป็นสำหรับการสร้างผลลัพธ์ที่แม่นยำและมีคุณภาพ
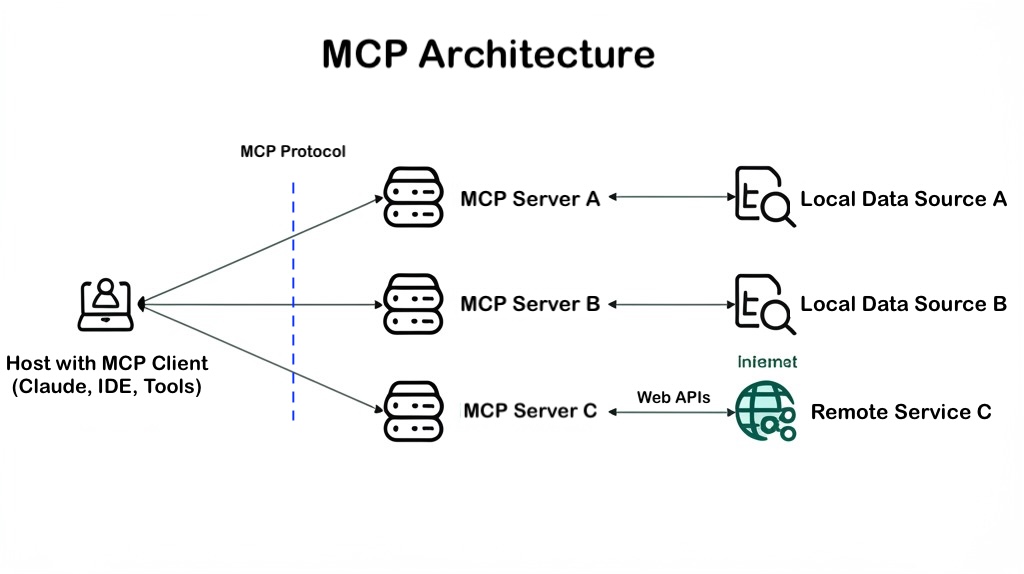
สถาปัตยกรรมทางเทคนิคของ MCP
MCP ถูกสร้างบนโมเดลแบบ client-server โดยได้รับแรงบันดาลใจจาก communication protocols ที่ได้รับการพิสูจน์แล้วอย่าง JSON-RPC 2.0 ซึ่งช่วยสร้างการเชื่อมต่อที่มีสถานะระหว่างส่วนประกอบต่างๆ
MCP Hosts: คือแอปพลิเคชันหรืออินเตอร์เฟสที่ผู้ใช้ใช้งาน เช่น chatbots, AI-powered IDEs หรือ custom agents ที่ต้องการเข้าถึงข้อมูลภายนอก
MCP Clients: ฝังอยู่ใน host applications เพื่อสร้างการเชื่อมต่อแบบ 1:1 กับ MCP server โดยรับหน้าที่ต่อรองความสามารถ ส่งคำขอ และจัดการผลลัพธ์
MCP Servers: โปรแกรมขนาดเล็กที่ให้ความสามารถเฉพาะแก่ระบบ AI ซึ่งสามารถเข้าถึงข้อมูลภายในเครื่อง (เช่น ไฟล์ ฐานข้อมูล) หรือบริการจากภายนอก (เช่น APIs) และคืนข้อมูลที่มีโครงสร้างผ่านสามองค์ประกอบหลัก:
Tools (Model-controlled): ฟังก์ชันหรือ API ที่ LLM เรียกใช้งานเพื่อดำเนินการต่างๆ เช่น การเรียก API หรือรันคำสั่ง
Resources (Application-controlled): แหล่งข้อมูลที่ LLM สามารถอ่านหรือค้นหาข้อมูลได้ เช่น เอกสาร ฐานข้อมูล หรือข้อมูลเว็บสด
Prompts (User-controlled): แบบแผนและคำสั่งที่ผู้ใช้กำหนดไว้ล่วงหน้าเพื่อชี้นำการใช้ tools และ resources ในการสร้างผลลัพธ์
Communication Transports: MCP รองรับวิธีการสื่อสารหลากหลายรูปแบบ ทั้งการเชื่อมต่อผ่าน subprocess ภายในเครื่องโดยใช้ standard input/output (stdio) และการเชื่อมต่อแบบระยะไกลผ่าน HTTP-based Server-Sent Events (SSE) ซึ่งช่วยให้สามารถรวมระบบกับแพลตฟอร์มที่แตกต่างกันได้อย่างยืดหยุ่น
ทำไมต้องใช้ MCP?
การผนวกเข้าด้วยกันอย่างมีมาตรฐาน (Standardization): ก่อน MCP การเชื่อมต่อ AI models กับเครื่องมือหรือแหล่งข้อมูลภายนอกต้องสร้างตัวเชื่อมที่แตกต่างกันสำหรับแต่ละตัว (ปัญหาแบบ M×N) แต่ MCP ช่วยลดความซับซ้อนลงเป็นแบบ M+N โดยให้นักพัฒนาสามารถสร้างหรือนำ connector มาตรฐานมาใช้ร่วมกับ client ที่รองรับ MCP
ระบบที่เป็นโมดูลและขยายตัวได้: การใช้ protocol ที่มีมาตรฐานช่วยให้ระบบแบ่งออกเป็นส่วนๆ ได้ง่าย ทำให้สามารถเพิ่มเครื่องมือหรือแหล่งข้อมูลใหม่เข้ามาได้โดยไม่ต้องเปลี่ยนแปลงโครงสร้างทั้งหมด เมื่อระบบเติบโต AI ก็ยังสามารถทำงานร่วมกับเครื่องมือต่างๆ ได้อย่างต่อเนื่อง
การให้ข้อมูลที่ครบถ้วนและมีความหมาย: MCP ถูกออกแบบมาเพื่อให้ LLM ได้รับข้อมูลที่จำเป็นอย่างครบถ้วน ไม่ใช่แค่ข้อมูลจากการฝึกหรืออินพุตจากผู้ใช้ แต่ยังดึงข้อมูลแบบเรียลไทม์ เช่น ข้อมูลจากการโต้ตอบที่ผ่านมา การตั้งค่า และข้อมูลไดนามิกอื่นๆ ทำให้ผลลัพธ์ที่ได้มีความแม่นยำและตรงจุด
ส่งเสริมระบบนิเวศที่ร่วมมือกัน: ด้วยมาตรฐานเปิดและ SDK ที่มีในหลายภาษา (Python, TypeScript, Java, Kotlin, C#) MCP เปิดโอกาสให้ทั้งภาคอุตสาหกรรมและชุมชนโอเพนซอร์สร่วมกันพัฒนานวัตกรรมใหม่ๆ ซึ่งเห็นได้จากการรวมระบบกับแพลตฟอร์มเช่น GitHub, Slack, Replit และ Codeium
ความปลอดภัยและการดูแลรักษาที่ง่ายขึ้น: การสร้างส่วนติดต่อระหว่าง LLM กับแหล่งข้อมูลให้เป็นมาตรฐาน ช่วยให้สามารถกำหนดนโยบายความปลอดภัยได้อย่างชัดเจน โดยแบ่งงานออกเป็น tools, resources และ prompts ทำให้ง่ายต่อการกำหนดสิทธิ์ ติดตามการไหลของข้อมูล และตรวจสอบปัญหาด้านความปลอดภัยอย่างเป็นระบบ
Setting Up Your Project
เราจะใช้ uv ซึ่งเป็น modern Python project manager สำหรับตั้งค่าและจัดการสภาพแวดล้อมการพัฒนา มันช่วยลดความซับซ้อนโดยดูแลงานติดตั้งแพ็กเกจที่คุณต้องการ สร้าง virtual environment และรันสคริปต์ของคุณ ทั้งหมดด้วยเครื่องมือเดียว
ขั้นตอนที่ 1: ติดตั้ง uv
macOS (ผู้เขียนใช้ MacBook)
เปิด terminal ของคุณและรันคำสั่งนี้เพื่อติดตั้ง uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
เมื่อติดตั้งเสร็จเรียบร้อยให้ปิดและเปิด terminal ใหม่ ลองเช็คดูว่า uv ได้ถูกติดตั้งสมบูรณ์ โดยพิมพ์คำสั่งนี้:
uv --version
ขั้นตอนที่ 2: สร้างโปรเจค
การสร้างโปรเจคด้วย uv สามารถทำได้ดังนี้
uv init PROJECT-NAME
ในที่นี้เราจะให้ชื่อโปรเจคว่า build-simple-mcp
uv init build-simple-mcp
cd build-simple-mcp
ขั้นตอนต่อมาให้สร้าง Environment สำหรับโปรเจค
source .venv/bin/activate
เมื่อเราได้ทำการ Activate ตัว Environment เรียบร้อย เราสามารถติดตั้ง Dependencies ต่างๆ ที่จะใช้ในโปรเจคนี้ ซึ่งประกอบด้วย
mcp[cli]: เป็น SDK ของ MCP และ command-line toolspandas: สำหรับอ่านไฟล์ CSV และ Parquetpyarrow: ทำให้สามารถอ่านไฟล์ Parquet ผ่าน Pandas ได้
สำหรับการติดตั้งให้พิมพ์คำสั่งดังนี้
uv add "mcp[cli]" pandas pyarrow
สร้าง folder และไฟล์ ต่างๆ ตามนี้
build-simple-mcp/
├── README.md
├── __pycache__/
├── data/ # สำหรับเก็บไฟล์ CSV และ Parquet
├── generate_parquet.py # ใช้สร้าง Parquet ไฟล์
├── main.py # โปรแกรมหลักสำหรับรัน MCP Server
├── pyproject.toml # ตั้งค่า build และ package Python
├── server.py # โปรแกรมสร้าง Server
├── tools/ # โฟล์เดอร์สำหรับ MCP Tools
├── utils/ # โฟล์เดอร์สำหรับไฟล์ที่เป็นฟังก์ชันต่างๆ
└── uv.lock # ล็อคเวอร์ชัน dependency ที่ Python เฉพาะ
คำสั่งในการสร้าง Folder และ File ผ่าน terminal ใน macOS ทำได้ดังนี้
# mkdir คือ การสร้างโฟล์เดอร์
mkdir data tools utils
# touch ใช้สำหรับสร้างไฟล์ใหม่
touch server.py
ขั้นตอนที่ 3: สร้างไฟล์จำลอง CSV และ Parquet
สำหรับบทความนี้ เราจะใช้ไฟล์ sample.csv เป็นตัวอย่าง
ให้ก็อบปี้ข้อมูลด้านล่างไปเก็บไว้ในไฟล์ sample.csv
id,name,email,date_of_birth
1,Peter Wong,peterw@thanawat.ai,20120402
2,Jane Smith,janesmith@thanawat.ai,20120515
3,John Doe,johndoe@thanawat.ai,20120620
4,Alice Brown,alice.brown@thanawat.ai,20120730
5,Robert Johnson,robertj@thanawat.ai,20120810
6,Linda Garcia,lindagarcia@thanawat.ai,20120925
7,Michael Davis,michaeld@thanawat.ai,20121012
8,Emily Wilson,emilyw@thanawat.ai,20121105
9,Chris Miller,chrism@thanawat.ai,20121218
10,Sarah Lee,sarahlee@thanawat.ai,20130103
สร้างไฟล์ generate_parquet.py
# Convert a CSV file to a Parquet file.
import pandas as pd
# Read CSV file into a DataFrame
df = pd.read_csv("data/sample.csv")
# Write the DataFrame to a Parquet file, excluding the index if specified
df.to_parquet("data/sample.parquet", index=False)
รันโปรแกรมที่เพิ่งสร้างเสร็จ
uv run generate_parquet.py
ถ้ารันสำเร็จในโฟล์เดอร์ data จะต้องมี 2 ไฟล์ตามนี้
data/
├── sample.csv # ไฟล์ sample ในฟอร์แมท CSV
├── sample.parquet # ไฟล์ sample ในฟอร์แมท Parquet
ไฟล์ CSV เป็นไฟล์ที่เราสามารถอ่านและเข้าใจได้ เหมาะสำหรับการเก็บข้อมูลจำนวนไม่เยอะ
ไฟล์ Parquet เป็นไฟล์ที่อยู่ในรูปแบบไบนารี่ และเก็บในลักษณะคอลัมน์ ทำให้งานต่อการนำไปประมวลผลทางคอมพิวเตอร์
การสร้างฟังก์ชันเพื่อจัดการไฟล์ CSV และ Parquet
ในขั้นตอนถัดไป เราจะพัฒนาชุด utility functions ที่สามารถโหลดไฟล์เหล่านี้และให้สรุปย่อเกี่ยวกับเนื้อหา — ฟังก์ชันเหล่านี้สามารถใช้งานร่วมกับ MCP tools ได้ง่าย
เมื่อมีข้อมูลแล้ว เราสามารถเขียน logic หลักเพื่อเปิดไฟล์และสร้างสรุปแบบง่ายๆ ได้
โค้ดนี้จะถูกเก็บไว้ใน Python module แยกในโฟลเดอร์ชื่อ utils/ ซึ่งช่วยให้เราสามารถนำไปใช้ซ้ำกับเครื่องมือต่างๆ โดยไม่ต้องเขียนใหม่
สร้างไฟล์ Python สำหรับอ่านไฟล์
สร้างไฟล์ file_reader.py ในโฟล์เดอร์ utils และก็อบปี้โค้ดด้านล่างนี้
import pandas as pd
from pathlib import Path
# Establish the base directory where our data files are stored
BASE_DATA_DIR = Path(__file__).resolve().parent.parent / "data"
def summarize_csv(file_name: str) -> str:
"""
Load a CSV file and generate a concise summary.
Parameters:
file_name (str): The name of the CSV file (e.g., 'data.csv').
Returns:
str: A description indicating the number of rows and columns.
"""
path_to_file = BASE_DATA_DIR / file_name
data_frame = pd.read_csv(path_to_file)
rows, columns = len(data_frame), len(data_frame.columns)
return f"CSV file '{file_name}' contains {rows} rows and {columns} columns."
def summarize_parquet(file_name: str) -> str:
"""
Load a Parquet file and generate a concise summary.
Parameters:
file_name (str): The name of the Parquet file (e.g., 'data.parquet').
Returns:
str: A description indicating the number of rows and columns.
"""
path_to_file = BASE_DATA_DIR / file_name
data_frame = pd.read_parquet(path_to_file)
rows, columns = len(data_frame), len(data_frame.columns)
return f"Parquet file '{file_name}' contains {rows} rows and {columns} columns."
อธิบายการทำงาน เราใช้ pandas เพื่อ import ไฟล์ CSV และ Parquet ซึ่งเป็นไลบรารี Python สำหรับการวิเคราะห์ข้อมูล นอกจากนี้ เรายังใช้ pathlib.Path เพื่อสร้างเส้นทางไฟล์ที่ทำงานได้อย่างราบรื่นในทุกระบบปฏิบัติการ
Packaging File Readers as MCP Tools
หลังจากเราได้พัฒนาฟังก์ชันเพื่อโหลดและสรุปข้อมูลจากไฟล์แล้ว ขั้นตอนต่อไปคือเปิดให้ความสามารถเหล่านี้ใช้งานกับ Claude ผ่าน MCP tools
MCP Tool คืออะไร?
MCP tool คือ Python function ที่คุณลงทะเบียนกับ MCP server เพื่อให้ AI สามารถเรียกใช้ฟังก์ชันนั้นเมื่อต้องทำงาน เช่น การอ่านไฟล์, การ query API หรือการคำนวณ
ในการลงทะเบียน tool ให้ decorate ฟังก์ชันด้วย @mcp.tool() ซึ่งจะสร้าง definition ที่ AI ใช้งานได้ แนวทางที่ดีที่สุดคือให้กำหนด instance ของ MCP server ไว้ที่จุดศูนย์กลางเดียว และ import ในทุกไฟล์ที่มี tool เพื่อรักษาความเป็นระเบียบและความสม่ำเสมอของโค้ด
ขั้นตอนที่ 1: ตั้งค่า MCP Server Instance
เริ่มต้นด้วยการเปิด (หรือสร้างใหม่หากจำเป็น) ไฟล์ server.py และ main.py ของคุณ จากนั้นให้เพิ่มโค้ดต่อไปนี้ลงในไฟล์เหล่านี้:
# server.py
from mcp.server.fastmcp import FastMCP
# สร้าง MCP server instance แบบกลางเพื่อใช้ร่วมกันในโปรเจกต์ของคุณ
mcp = FastMCP("build-simple-mcp")
# main.py
from server import mcp
# เปิดเซิร์ฟเวอร์เมื่อสคริปต์นี้ถูกเรียกใช้งานโดยตรง
if __name__ == "__main__":
mcp.run()
ขั้นตอนที่ 2: สร้างเครื่องมือ CSV
ตอนนี้ถึงเวลาที่เราจะสร้างเครื่องมือแรกของเรา — ฟังก์ชันที่ให้สรุปข้อมูลของไฟล์ CSV ให้เริ่มต้นด้วยการสร้างไฟล์ชื่อ csv_tools.py ในไดเรกทอรี tools/
tools/
├── csv_tools.py # ไฟล์เครื่องมือ CSV
คัดลอกโค้ดด้านล่างนี้ไปไว้ใน csv_tools.py
from server import mcp
from utils.file_reader import read_csv_summary
@mcp.tool()
def summarize_csv_file(filename: str) -> str:
"""
Generates a summary of a CSV file by counting its rows and columns.
Parameters:
filename (str): The name of the CSV file located in the /data directory (e.g., 'sample.csv').
Returns:
str: A description outlining the dimensions of the CSV file.
"""
return read_csv_summary(filename)
ขั้นตอนที่ 3: สร้างเครื่องมือสำหรับไฟล์ Parquet
ตอนนี้ให้ทำเช่นเดียวกันสำหรับไฟล์ Parquet
สร้างไฟล์ชื่อ parquet_tools.py ในโฟลเดอร์ tools/
tools/
├── parquet_tools.py # ไฟล์เครื่องมือ Parquet
คัดลอกโค้ด้านล่างไว้ใน parquet_tools.py
from server import mcp
from utils.file_reader import read_parquet_summary
@mcp.tool()
def summarize_parquet_file(filename: str) -> str:
"""
Provides a summary of a Parquet file by determining its row and column counts.
Parameters:
filename (str): The name of the Parquet file stored in the /data folder (e.g., 'sample.parquet').
Returns:
str: A brief description detailing the dimensions of the file.
"""
return read_parquet_summary(filename)
ขั้นตอนที่ 4: ลงทะเบียน MCP Tools
เนื่องจาก MCP tools จะถูกเปิดใช้งานทันทีเมื่อโมดูลถูก import (ขอบคุณ decorators) สิ่งที่คุณต้องทำคือ import โมดูลเหล่านี้ในไฟล์หลักของคุณ โดยให้นำบรรทัดโค้ดต่อไปนี้ไปวางที่ส่วนเริ่มต้นของไฟล์ main.py ของคุณ
# main.py
from server import mcp
import tools.csv_tools
import tools.parquet_tools
# เปิดเซิร์ฟเวอร์เมื่อสคริปต์นี้ถูกเรียกใช้งานโดยตรง
if __name__ == "__main__":
mcp.run()
เมื่อเซิร์ฟเวอร์เริ่มทำงานแล้ว มันจะลงทะเบียนเครื่องมือทั้งหมดโดยอัตโนมัติด้วย @mcp.tool() decorators ทันทีที่มีการ import
เครื่องมือของคุณพร้อมใช้งานแล้ว! ในส่วนถัดไป เราจะอธิบายขั้นตอนการเปิดเซิร์ฟเวอร์และเชื่อมต่อกับ Claude for Desktop เพื่อให้คุณได้ทดลองใช้คำสั่งผ่านข้อความ
การรันและทดสอบ MCP Server กับ Claude for Desktop
ตอนนี้คุณมี MCP server ที่ใช้งานได้เต็มที่ พร้อมเครื่องมือสองตัว ได้แก่ เครื่องมือสำหรับสรุปข้อมูลไฟล์ CSV และเครื่องมือสำหรับไฟล์ Parquet
ถึงเวลาที่จะเปิดใช้งาน server ของคุณและเชื่อมต่อกับ Claude for Desktop เพื่อให้คุณสามารถเรียกใช้เครื่องมือเหล่านี้ด้วยคำสั่งที่ชัดเจน
ในขั้นตอนถัดไป คุณจะเริ่ม server และตั้งค่าการเชื่อมต่อ เพื่อให้คุณได้ทดสอบและโต้ตอบกับเครื่องมือผ่านคำสั่ง
ขั้นตอนที่ 1: เริ่มเซิร์ฟเวอร์
เริ่มจากการเปิดเซิร์ฟเวอร์บนเครื่อง local ของคุณ จากนั้นไปที่ root directory ของโปรเจ็กต์ (ที่ไฟล์ main.py อยู่) แล้วรันคำสั่งดังต่อไปนี้:
uv run main.py
คำสั่งนี้ทำให้ MCP server ของคุณและเครื่องมือที่ตั้งค่าไว้เริ่มทำงาน แม้ terminal อาจไม่แสดงรายละเอียดมากในตอนแรก แต่คุณสามารถมั่นใจได้ว่า server ทำงานอยู่และพร้อมรับการเชื่อมต่อจาก client อย่าง Claude
ขั้นตอนที่ 2: ติดตั้ง Claude for Desktop (ถ้ายังไม่ได้ติดตั้ง)
เพื่อเชื่อมต่อกับ MCP server คุณต้องติดตั้ง Claude for Desktop ในเครื่องของคุณ ให้ทำตามขั้นตอนนี้:
- ดาวน์โหลด Claude for Desktop จากเว็บไซต์ของ Anthropic
- ติดตั้งแอปพลิเคชันตามคำแนะนำสำหรับระบบปฏิบัติการที่คุณใช้
หมายเหตุ: ปัจจุบัน Claude for Desktop ยังไม่รองรับ Linux หากคุณใช้ Linux กรุณาอ้างอิงส่วนที่อธิบายการสร้าง MCP client ด้วยตนเอง
ขั้นตอนที่ 3: ตั้งค่าให้ Claude เชื่อมต่อกับเซิร์ฟเวอร์ของคุณ
Claude ต้องการที่อยู่เซิร์ฟเวอร์เพื่อเข้าถึง MCP server ของคุณ ในการตั้งค่านี้ คุณต้องแก้ไขไฟล์ configuration บนคอมพิวเตอร์ของคุณ
สำหรับ MacOS:
เปิดไฟล์ claude_desktop_config.json ในโปรแกรม code editor ที่คุณชอบ (สร้างไฟล์ขึ้นมาหากยังไม่มี):
(~/Library/Application Support/Claude/claude_desktoop_config.json)
ไฟล์นี้จะช่วยให้คุณระบุรายละเอียดการเชื่อมต่อที่จำเป็น เพื่อให้ Claude สามารถค้นหาและติดต่อกับ MCP server ของคุณได้
vi ~/Library/Application\ Support/Claude/claude_desktop_config.json
ขั้นตอนที่ 4: ระบุรายละเอียดเซิร์ฟเวอร์ของคุณในไฟล์ config
คัดลอกและวาง JSON snippet ต่อไปนี้ลงในไฟล์ configuration ของคุณ อย่าลืมแทนที่ “/ABSOLUTE/PATH/…” ด้วย path แบบ absolute ของไดเรกทอรีโปรเจกต์ build-simple-mcp ของคุณ
การตั้งค่านี้จะบอกให้ Claude ทราบว่าเซิร์ฟเวอร์ MCP ของคุณอยู่ที่ไหน เพื่อให้สามารถเชื่อมต่อและโต้ตอบกับเครื่องมือของคุณได้อย่างง่ายดาย
{
"mcpServers": {
"build-simple-mcp": {
"command": "uv",
"args": [
"--directory",
"/ABSOLUTE/PATH/TO/build-simple-mcp",
"run",
"main.py"
]
}
}
}
ตรวจสอบให้แน่ใจว่า uv executable อยู่ใน PATH ของระบบของคุณ หากไม่ ให้ปรับปรุงการตั้งค่าโดยเปลี่ยน "command": "uv" เป็น path เต็มของ uv executable บนเครื่องของคุณ
ขั้นตอนที่ 5: รีสตาร์ท Claude for Desktop เพื่อทดสอบ MCP Server
 Claude for Desktop with tools and MCP server.
Claude for Desktop with tools and MCP server.
รีสตาร์ทแอปพลิเคชัน Claude for Desktop เมื่อโปรแกรมเริ่มใหม่ คุณจะสังเกตเห็นไอคอนเครื่องมือใหม่ (รูปค้อน) ในอินเทอร์เฟซ การคลิกที่ไอคอนนี้จะแสดงเครื่องมือที่ลงทะเบียนไว้ดังนี้:
- summarize_csv_file
- summarize_parquet_file
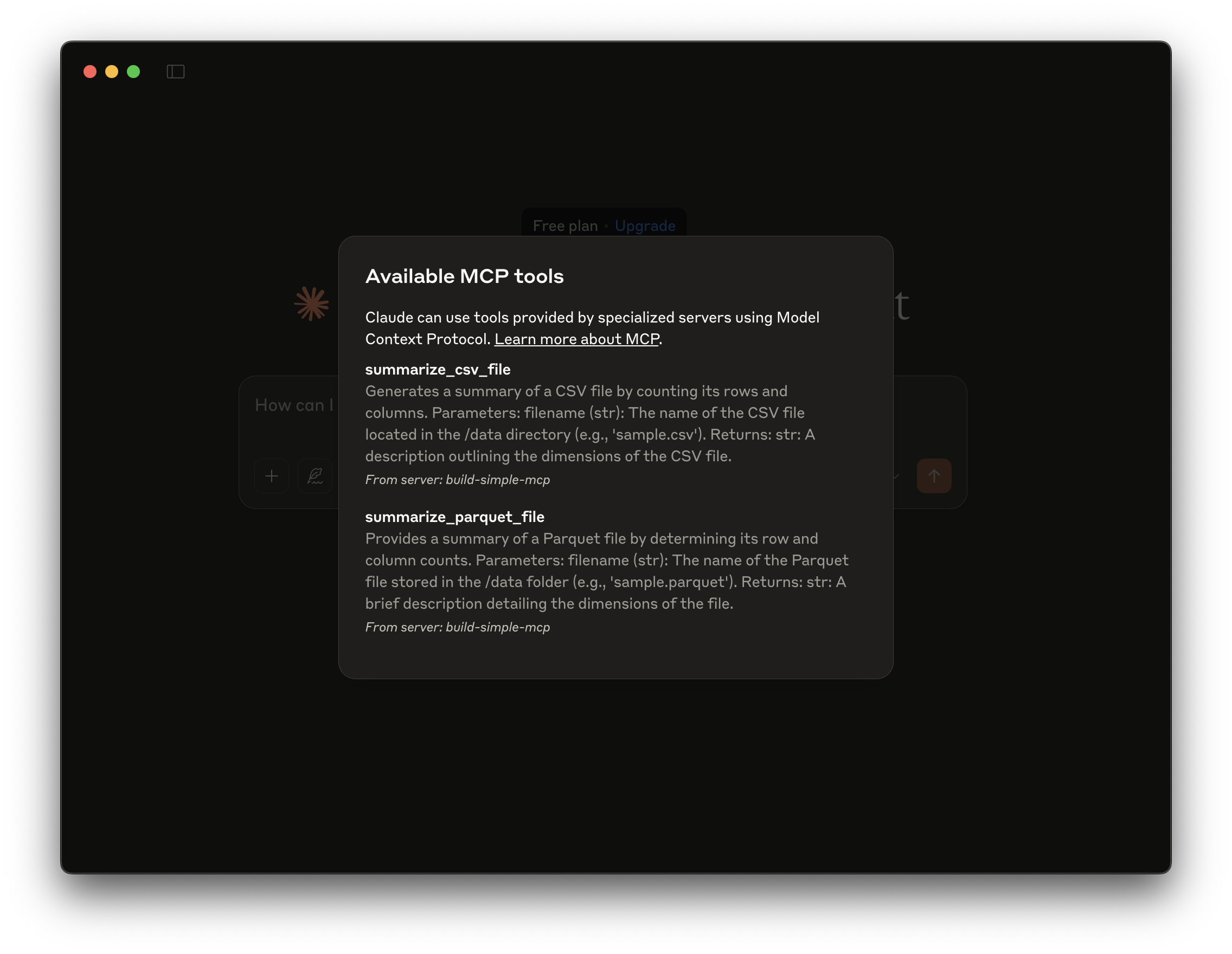 Summarize CSV File and Summarize Parquet File Tools.
Summarize CSV File and Summarize Parquet File Tools.
ตอนนี้คุณสามารถทดสอบเครื่องมือได้โดยถาม Claude ว่า:
- “สรุปไฟล์ CSV ชื่อ sample.csv”
- “ใน sample.parquet มีแถวกี่แถว?”
 Claude automatically selected the tools.
Claude automatically selected the tools.
Claude จะเลือกเครื่องมือที่ถูกต้องโดยอัตโนมัติ เชื่อมต่อกับเซิร์ฟเวอร์ของคุณ และแสดงผลตาม Python code ที่คุณเขียนไว้
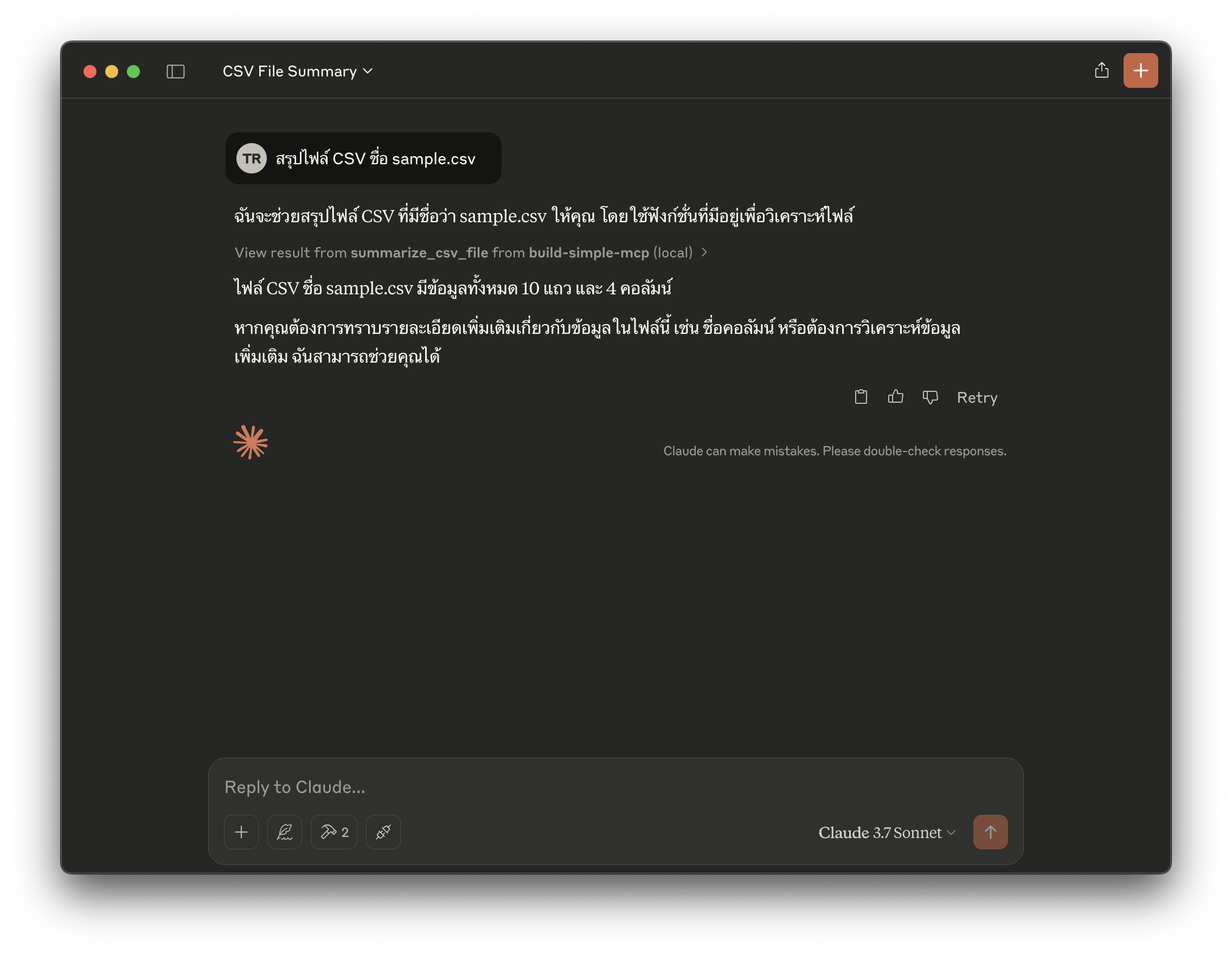 Chat message from Claude.
Chat message from Claude.
สามารถเข้าไปดูโค้ดได้ที่ GitHub

{kind=link}